Traveling Salesman Problem (TSP) Environment#
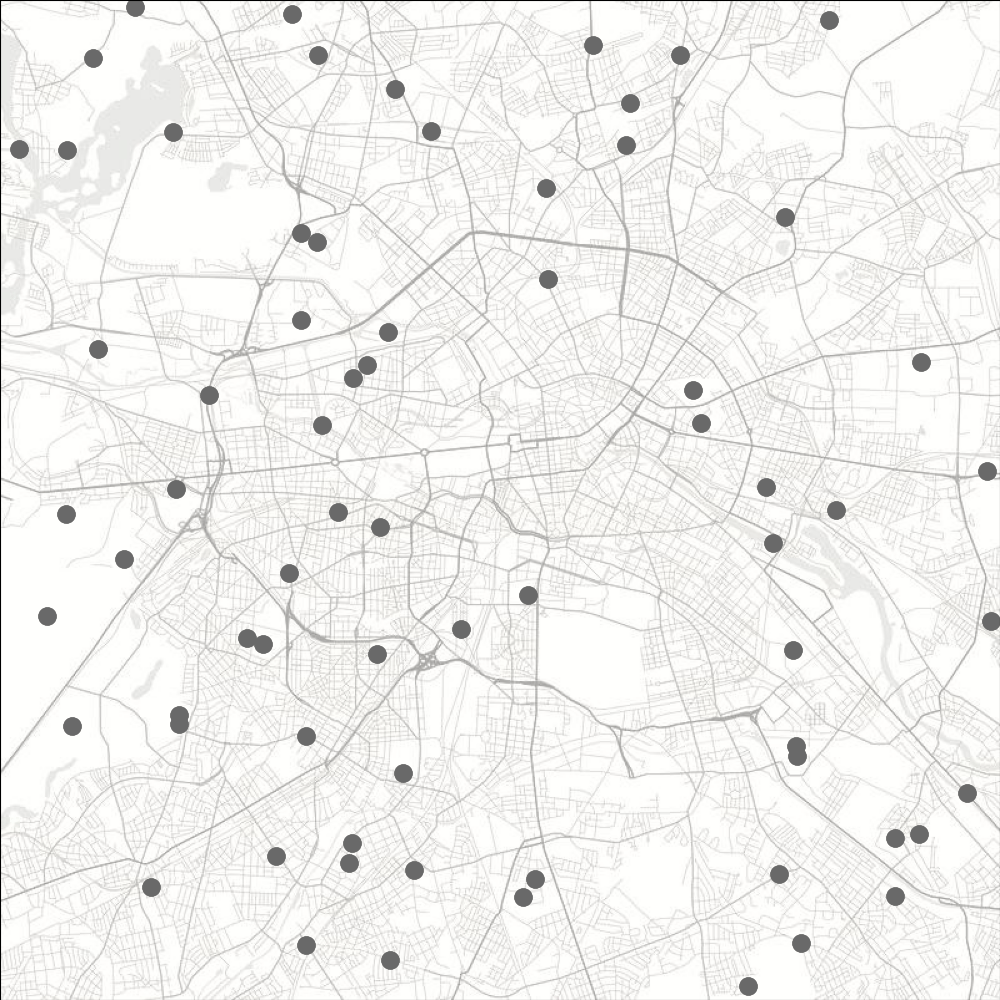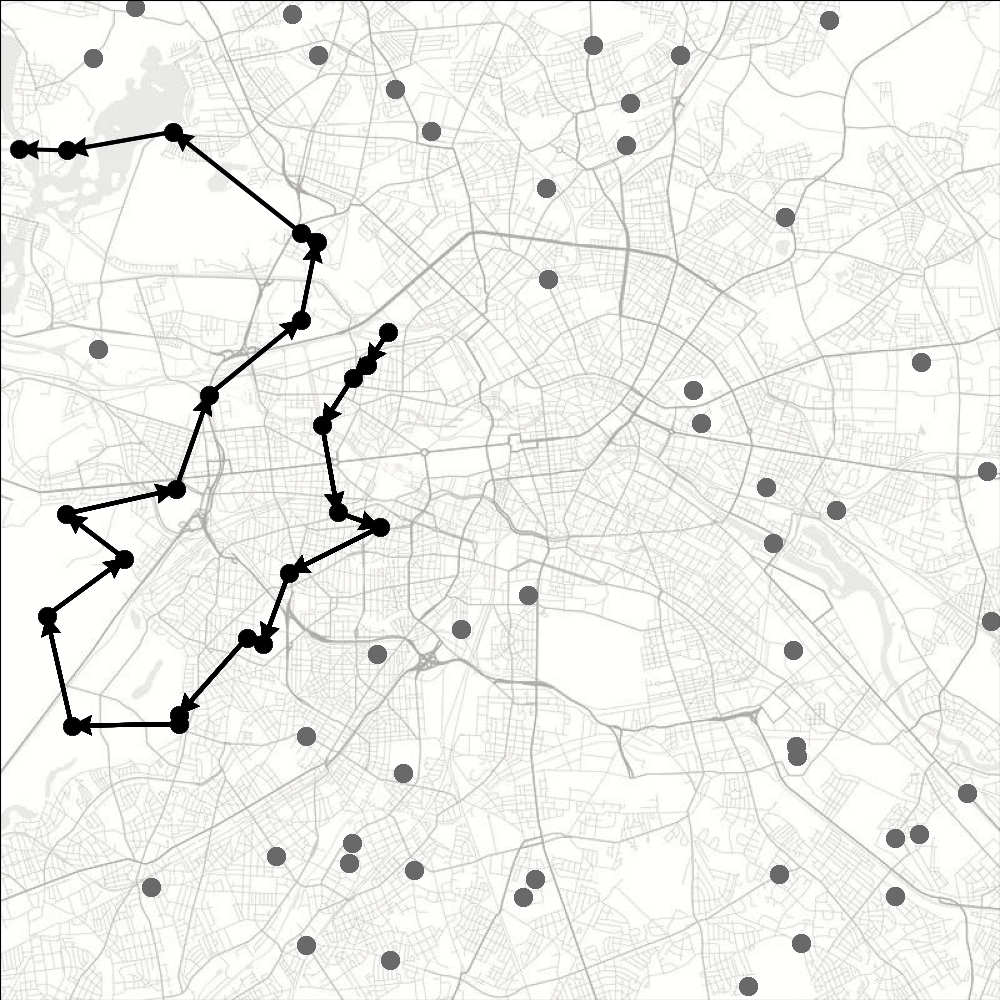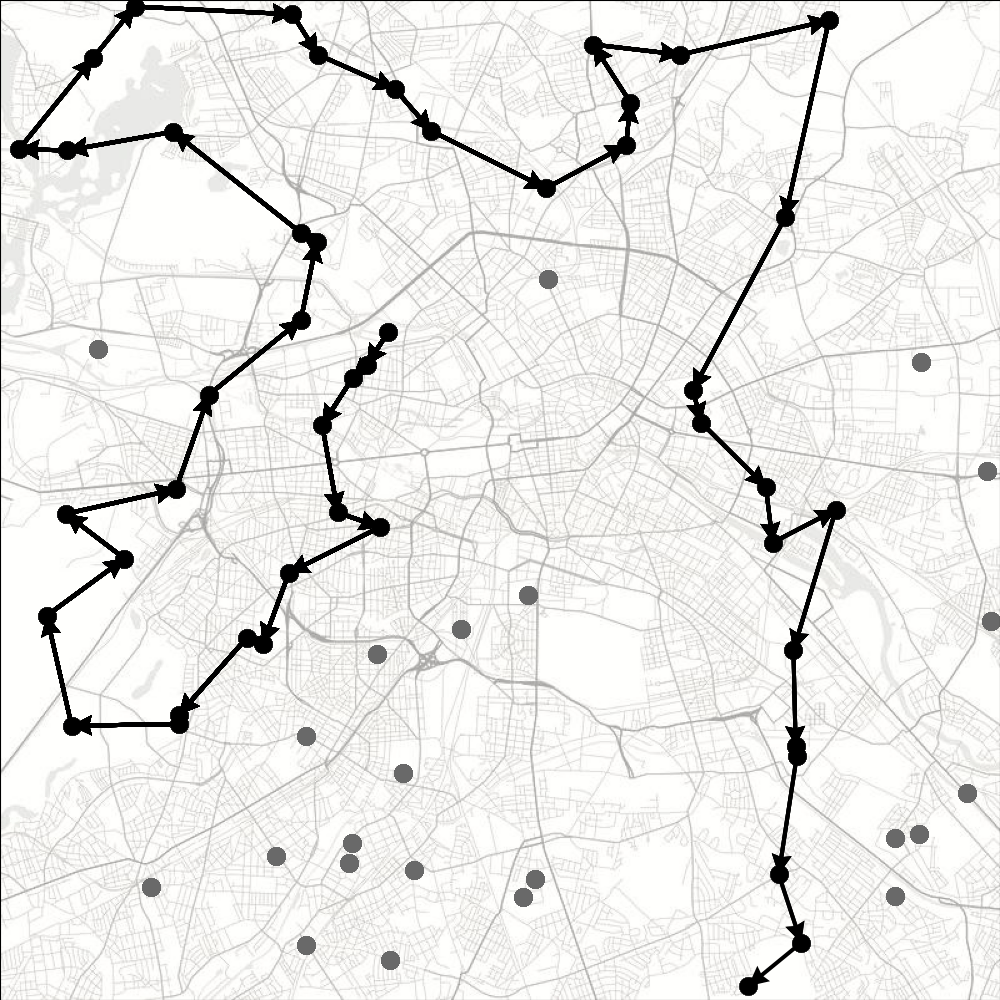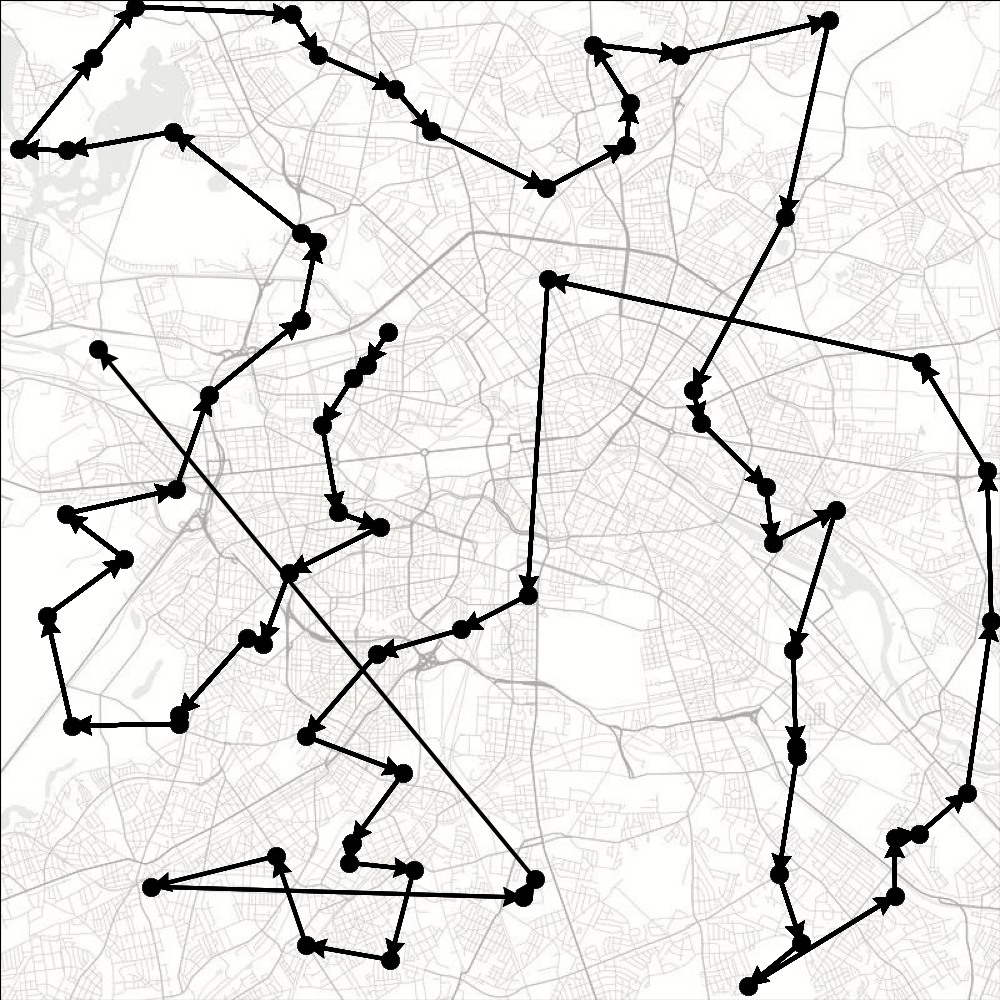
We provide here a Jax JIT-able implementation of the traveling salesman problem (TSP).
TSP is a well-known combinatorial optimization problem. Given a set of cities and the distances between them, the goal is to determine the shortest route that visits each city exactly once and finishes in the starting city. The problem is NP-complete, thus there is no known algorithm both correct and fast (i.e., that runs in polynomial time) for any instance of the problem.
When the environment is reset, a new problem instance is generated by sampling coordinates (a pair for each city) from a uniform distribution between 0 and 1. The number of cities is a parameter of the environment. A trajectory terminates when no new cities can be visited or the last action was invalid (i.e., the agent attempted to revisit a city).
Observation#
The observation given to the agent provides information on the problem layout, the visited/unvisited cities and the current position (city) of the agent.
-
coordinates: jax array (float) of shape(num_cities, 2), array of coordinates of each city. -
position: jax array (int32) of shape(), identifier (index) of the last visited city. -
trajectory: jax array (int32) of shape(num_cities,), city indices defining the route (-1--> not filled yet). -
action_mask: jax array (bool) of shape(num_cities,), binary values denoting whether a city can be visited.
Action#
The action space is a DiscreteArray of integer values in the range of [0, num_cities-1]. An
action is the index of the next city to visit.
Reward#
The reward could be either:
-
Dense: the negative distance between the current city and the chosen next city to go to. It is 0 for the first chosen city, and for the last city, it also includes the distance to the initial city to complete the tour.
-
Sparse: the negative tour length at the end of the episode. The tour length is defined as the sum of the distances between consecutive cities. It is computed by starting at the first city and ending there, after visiting all the cities.
In both cases, the reward is a large negative penalty of -num_cities * sqrt(2) if
the action is invalid, i.e. a previously selected city is selected again.
Registered Versions 📖#
TSP-v1: TSP problem with 20 randomly generated cities and a dense reward function.